We use cookies to improve your browsing experience, support the operation of this site, and understand how visitors use our content.
You can accept all cookies, accept only essential cookies, or deny non-essential cookies.
Privacy Policy
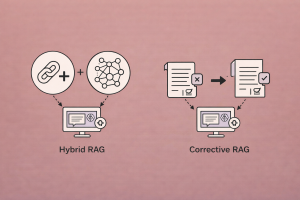
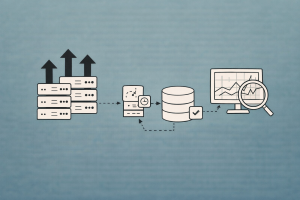
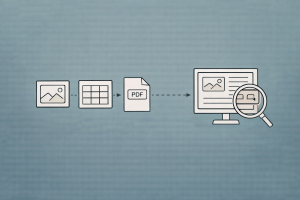
RAG (Retrieval-Augmented Generation) Tutorials
Technical tutorials on RAG: retrieval-augmented generation, multimodal RAG, indexing, chunking, and more.